Target 👇

Shape a Pile of Granules into a 'T' (12×)
Target 👇

Shape a Rope into a Circle (12×)
Target 👇

T-shirt Unfolding (8×)
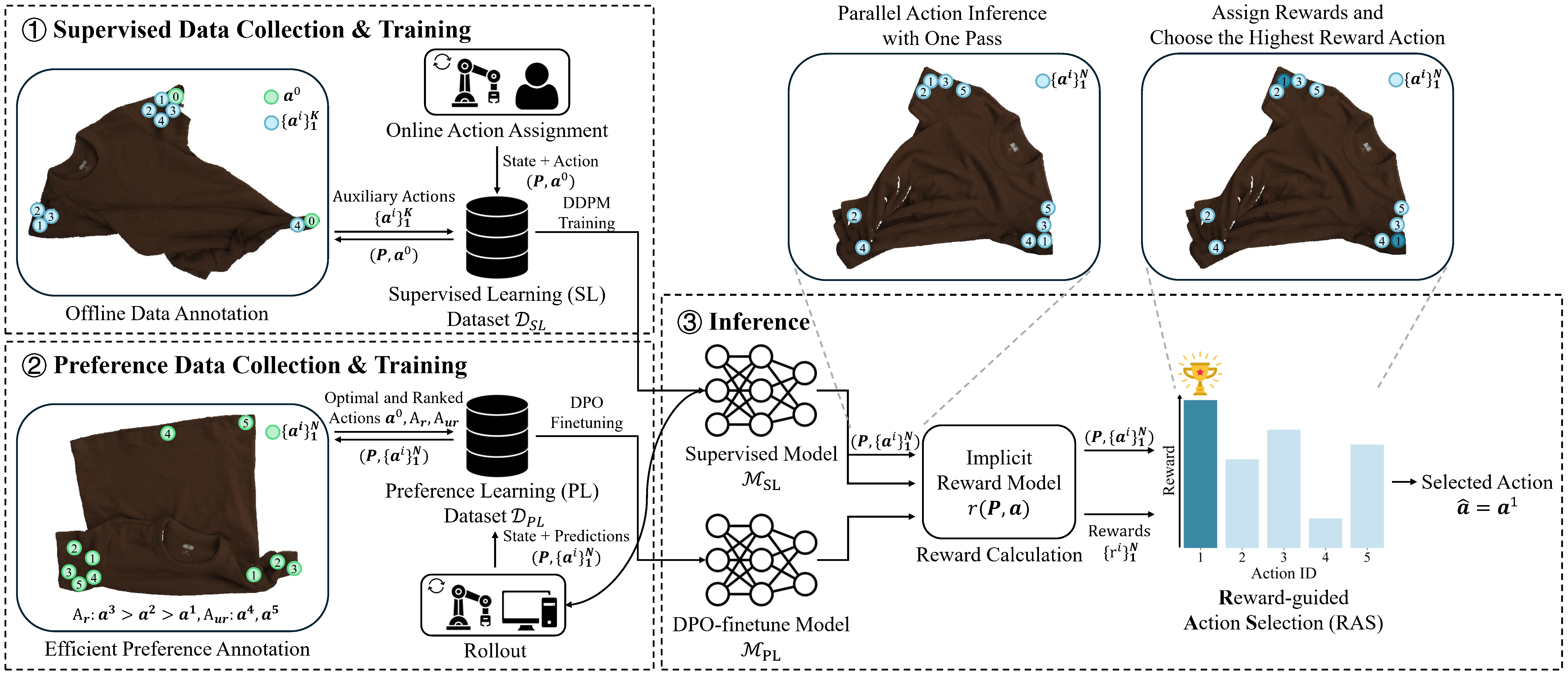
Fig. 1: Pipeline overview of DeformPAM. (1) In stage 1, we assign actions for execution and annotate auxiliary actions for supervised learning in a real-world environment and train a supervised primitive model based on Diffusion. (2) In stage 2, we deploy this model in the environment to collect preference data composed of annotated and predicted actions. These data are used to train a DPO-finetuned model. (3) During inference, we utilize the supervised model to predict actions and employ an implicit reward model derived from two models for Reward-guided Action Selection (RAS). The action with the highest reward is regarded as the final prediction.
(a)
(b)






























(c)
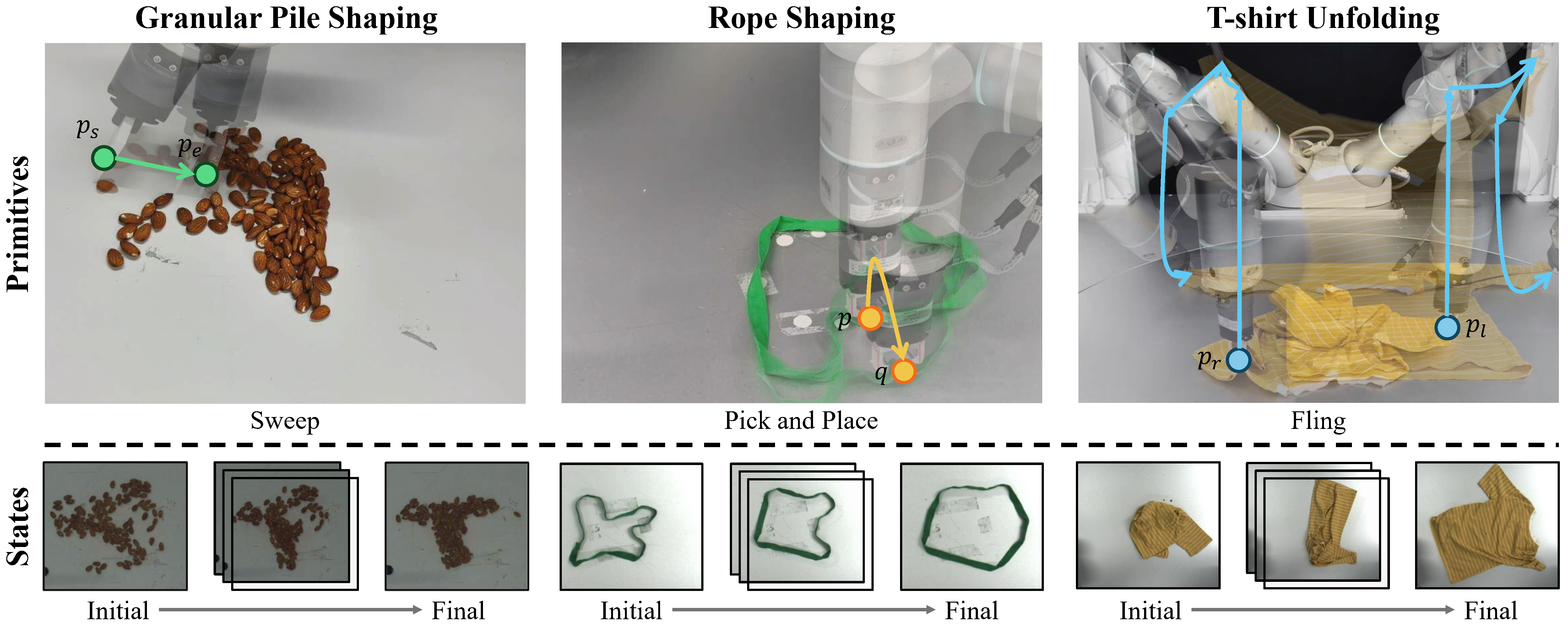
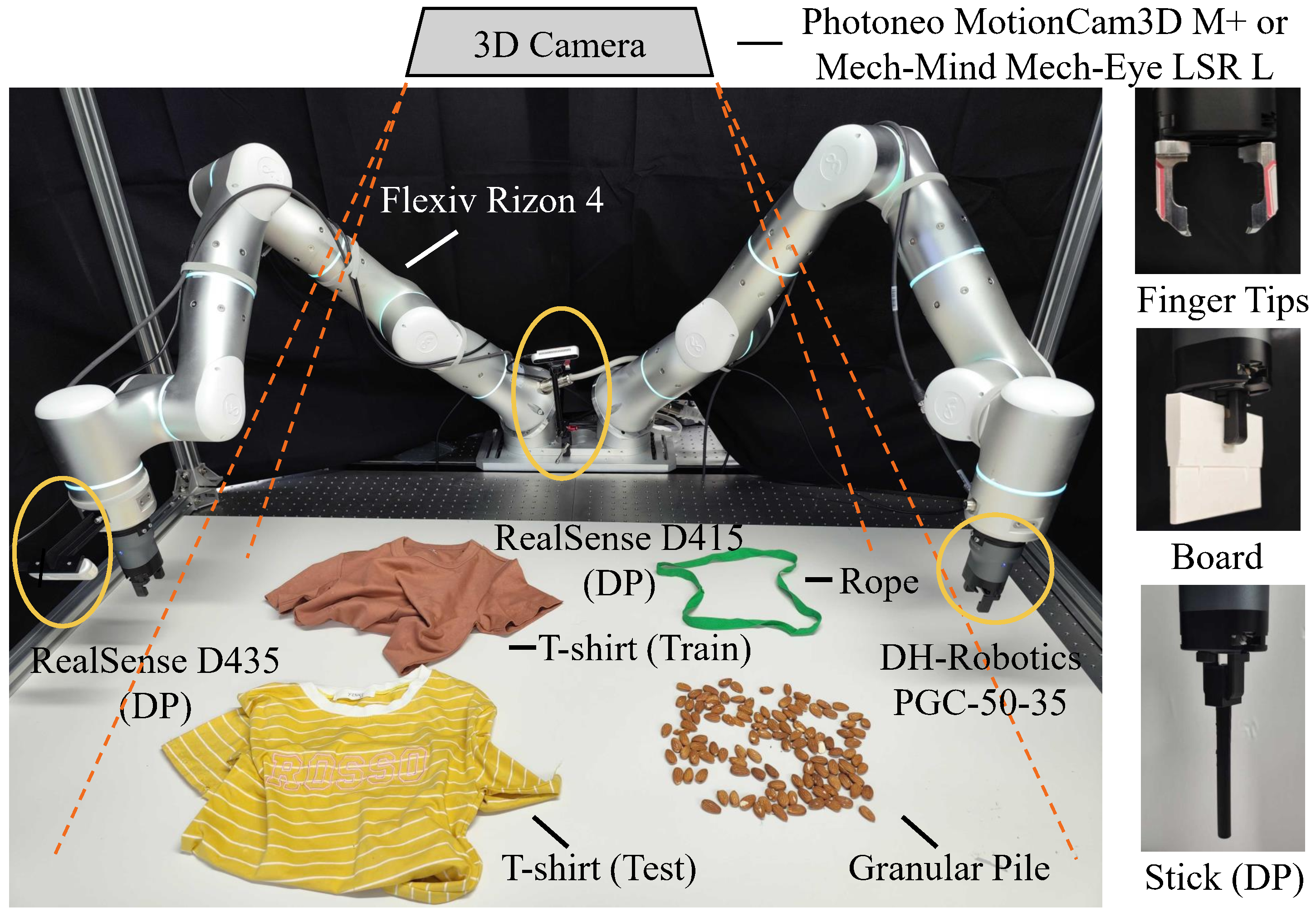
Fig. 2: (a) Object states and primitives of each task. Beginning with a random complex state of an object, multiple steps of action primitives are performed to gradually achieve the target state. (b) Hardware setup and tools used in our real-world experiments. Devices and tools marked with DP are not used in primitive-based methods. (c) Some of the initial states of the three tasks during evaluation. The initial states are random and complex, which makes the tasks challenging.
For primitive-based methods and the Diffusion Policy, we collect a comparable amount of data to ensure a fair comparison. Additionally, it is noted that the primitive-based methods (including ours) are more efficient in terms of training time.
TABLE I: The dataset size of each model and each task. # seq. and # states indicate the number of task sequences and states.
| Granular Pile Shaping | Rope Shaping | T-shirt Unfolding | ||||
|---|---|---|---|---|---|---|
| # seq. | # states | # seq. | # states | # seq. | # states | |
| Primitive-Based (Stage 1) | ~ 60 | 400 | ~ 30 | 200 | ~ 90 | 200 |
| Primitive-Based (Stage 2) | ~ 25 | 200 | ~ 10 | 100 | ~ 50 | 146 |
| Diffusion Policy | 60 | 29807 | 50 | 9971 | - | - |
(a) Granular Pile Shaping
(b) Rope Shaping
Fig. 3: Training time of primitive-based methods and the Diffusion Policy. The results are tested on a single NVIDIA RTX 4090.
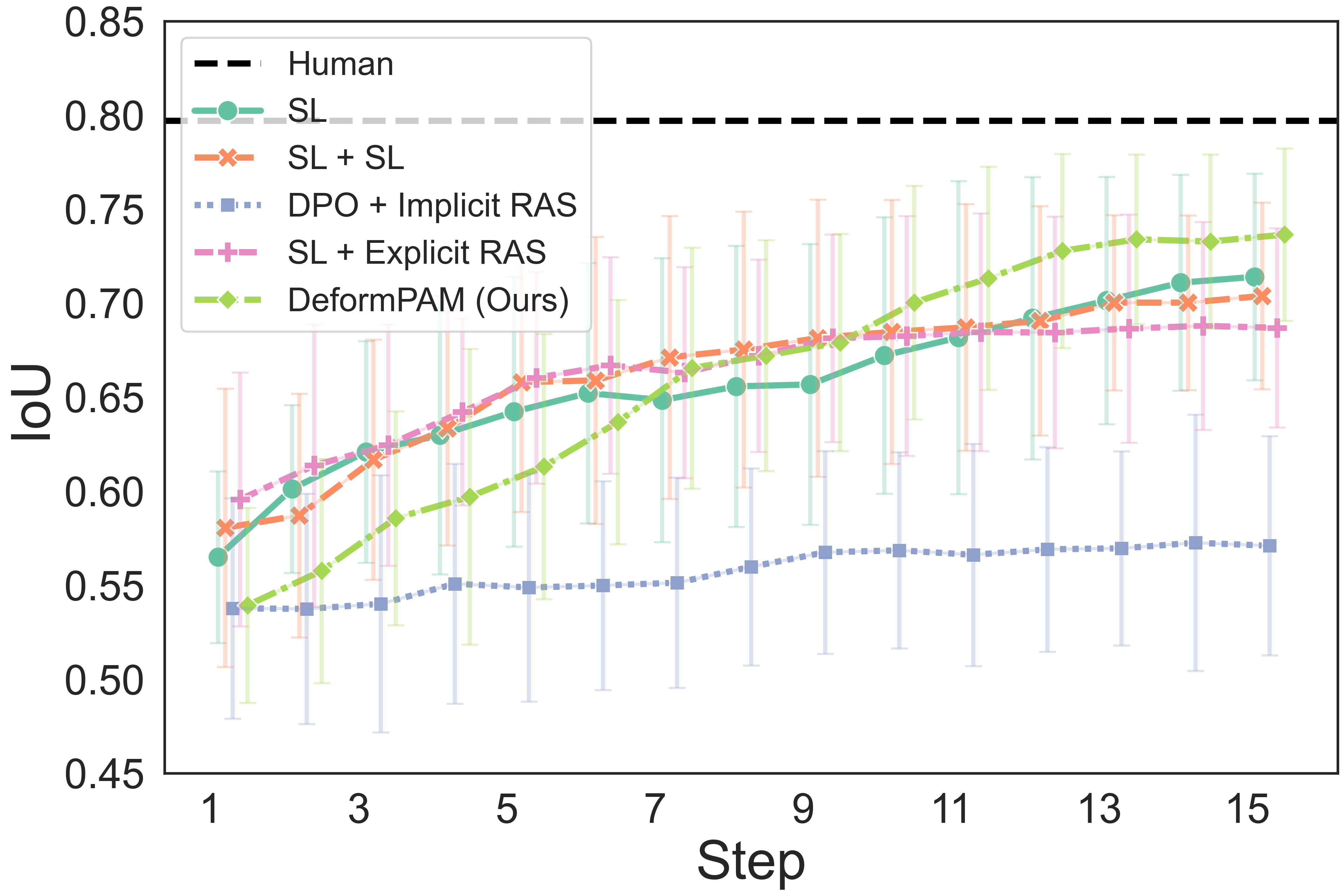
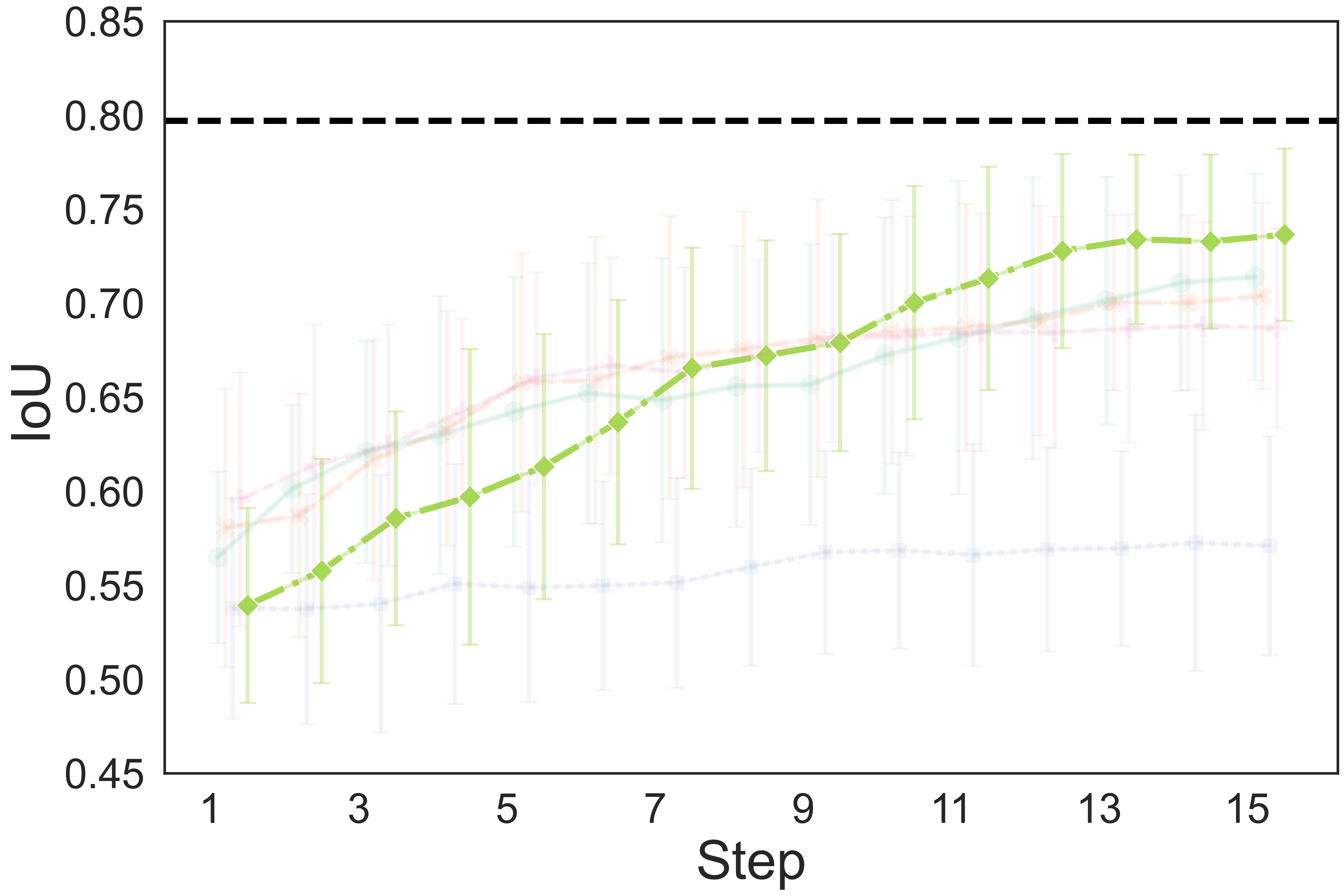
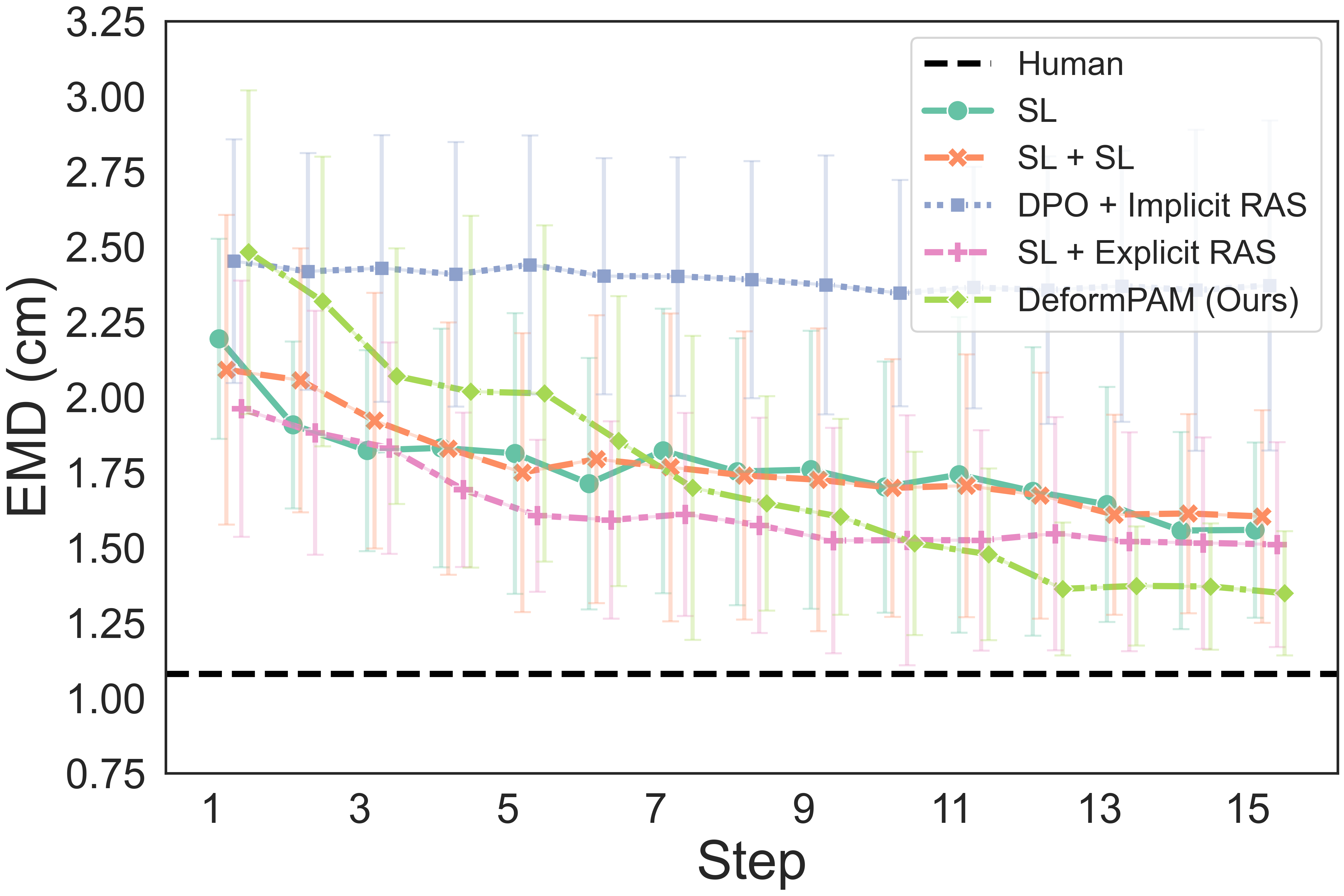
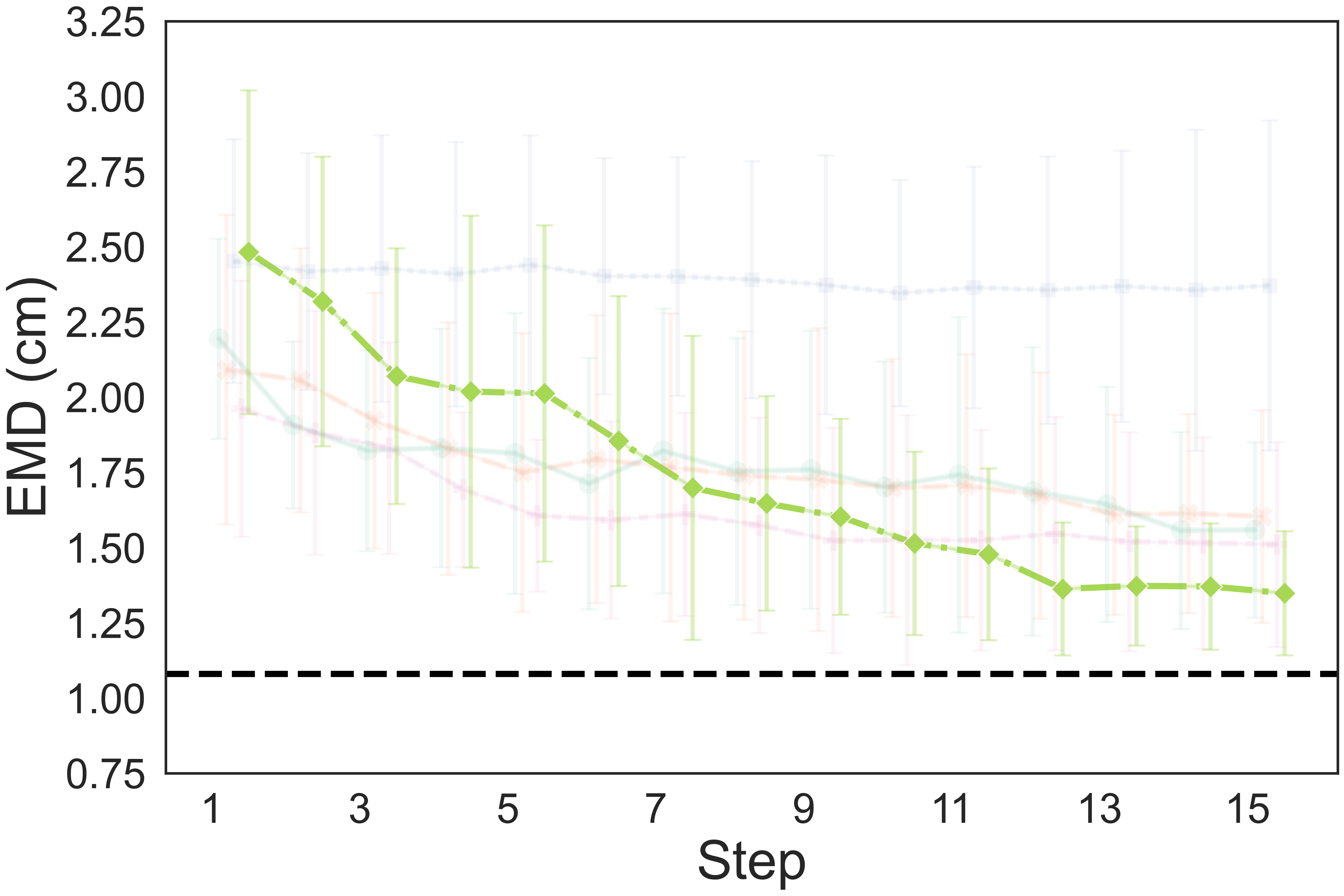
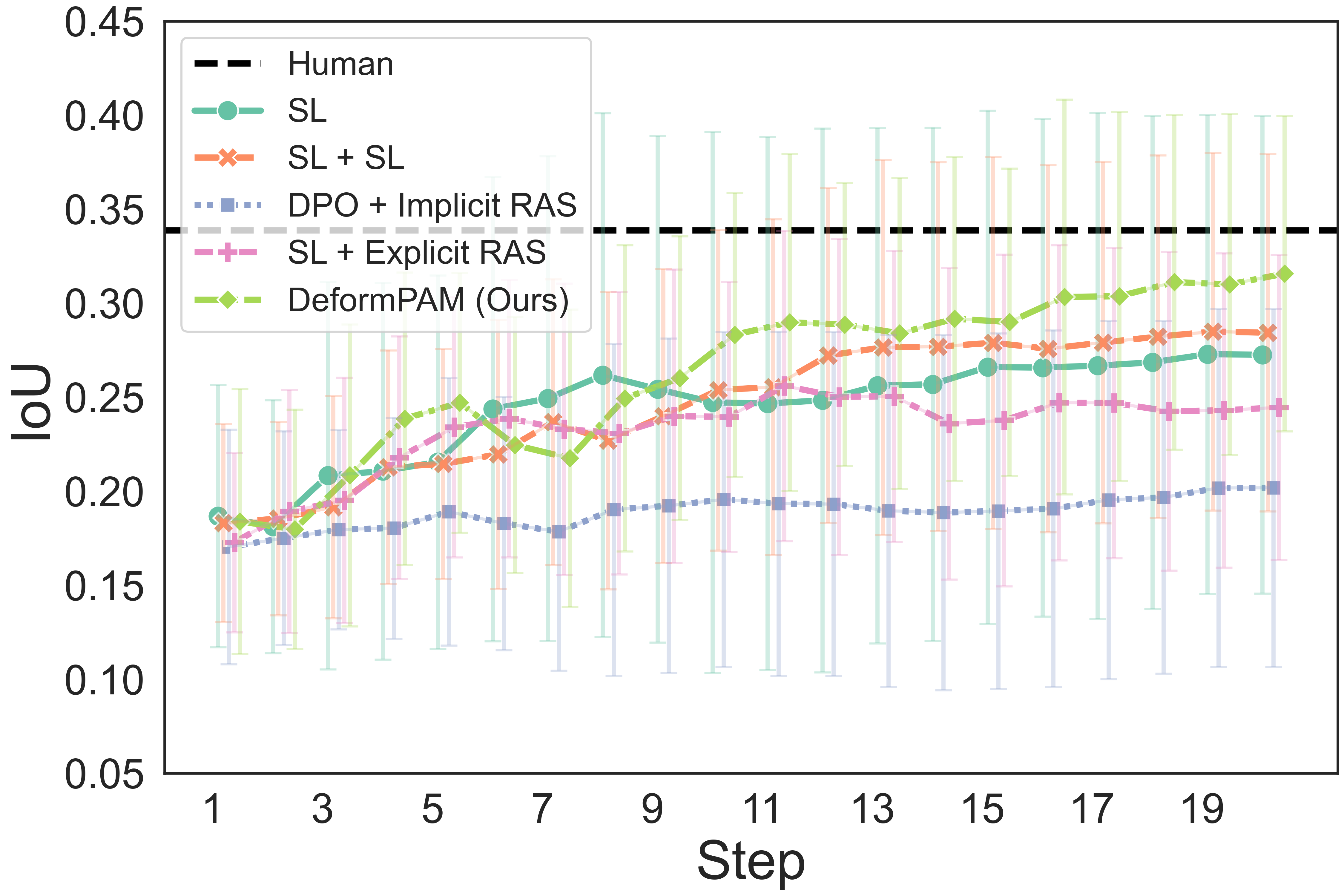
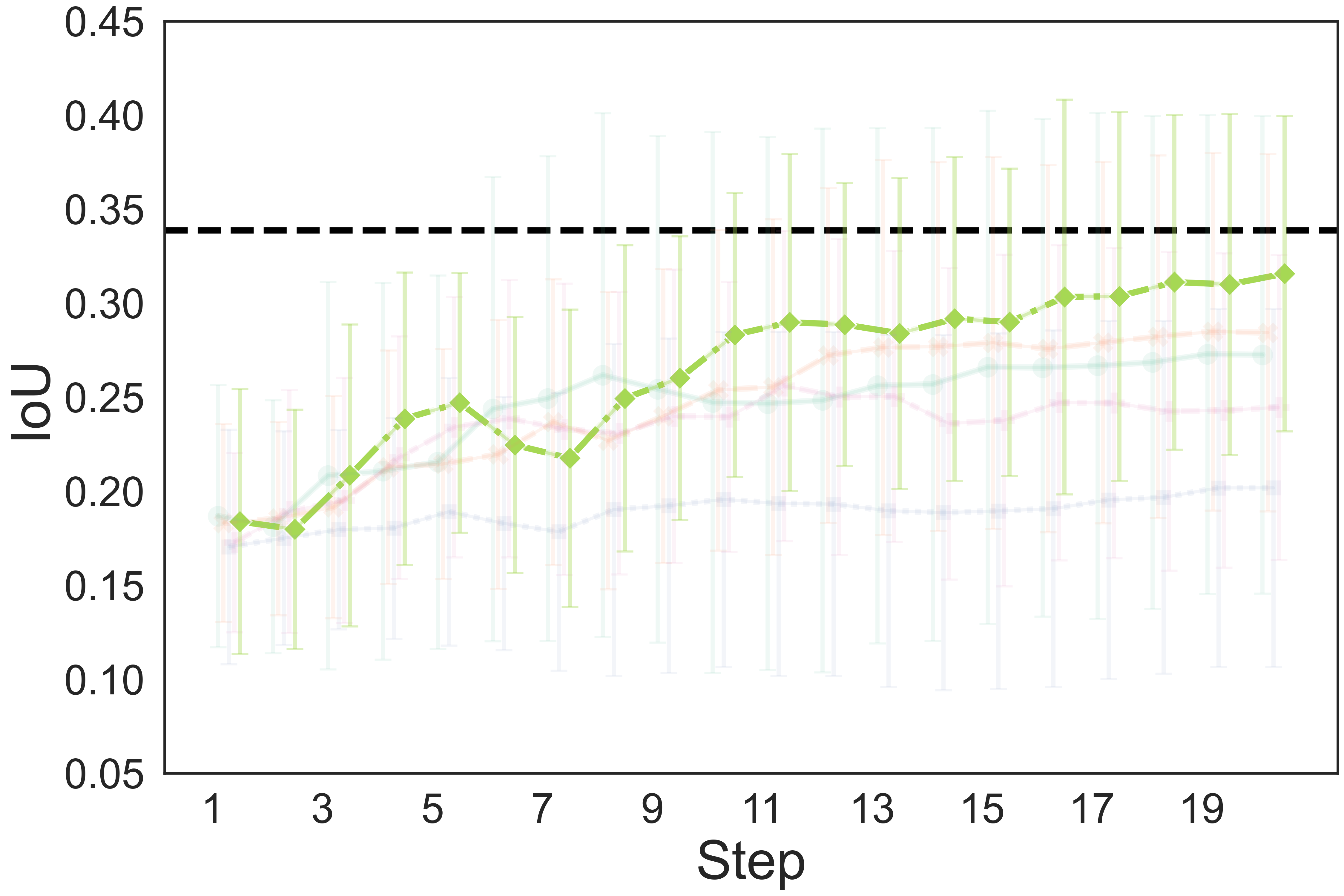
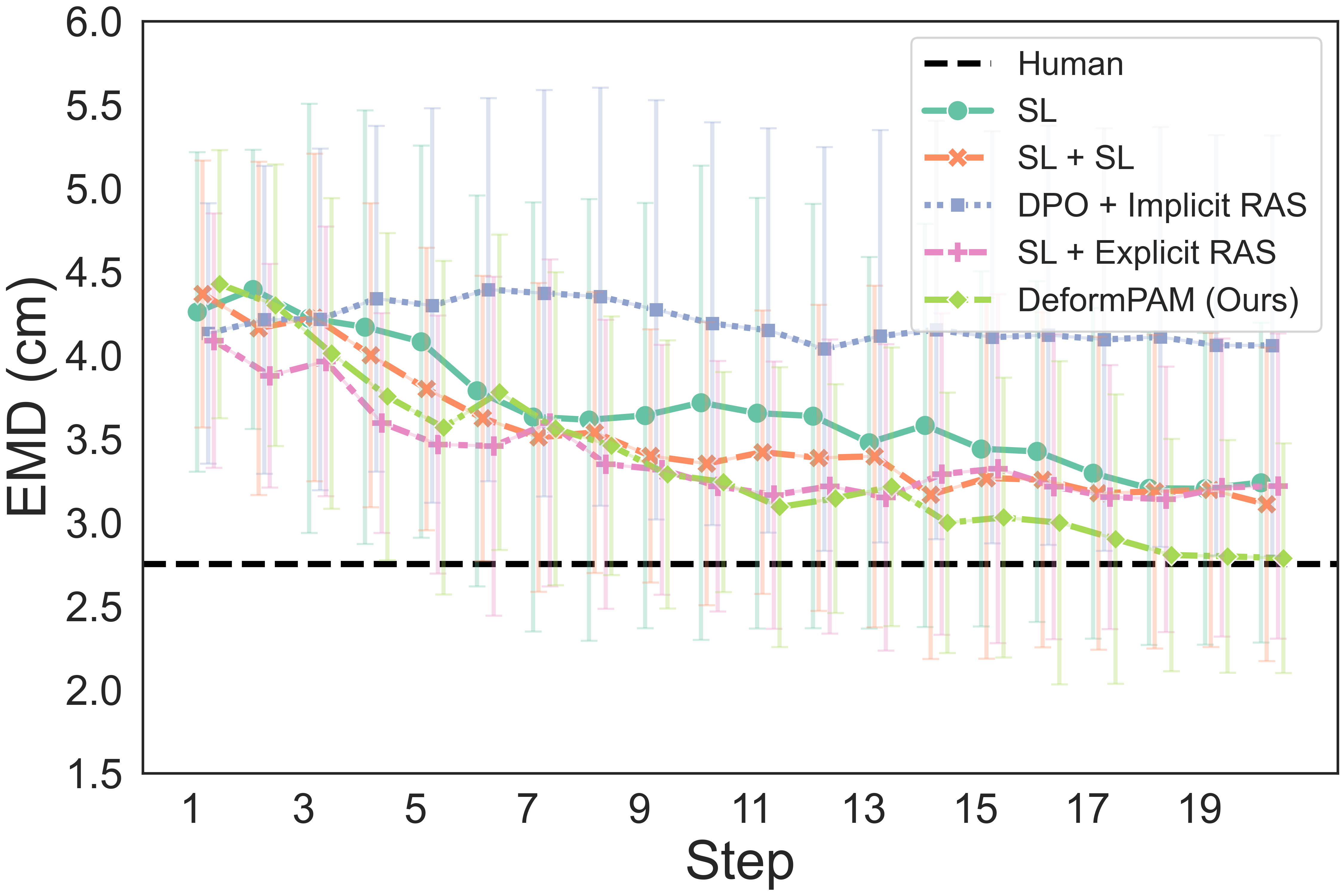
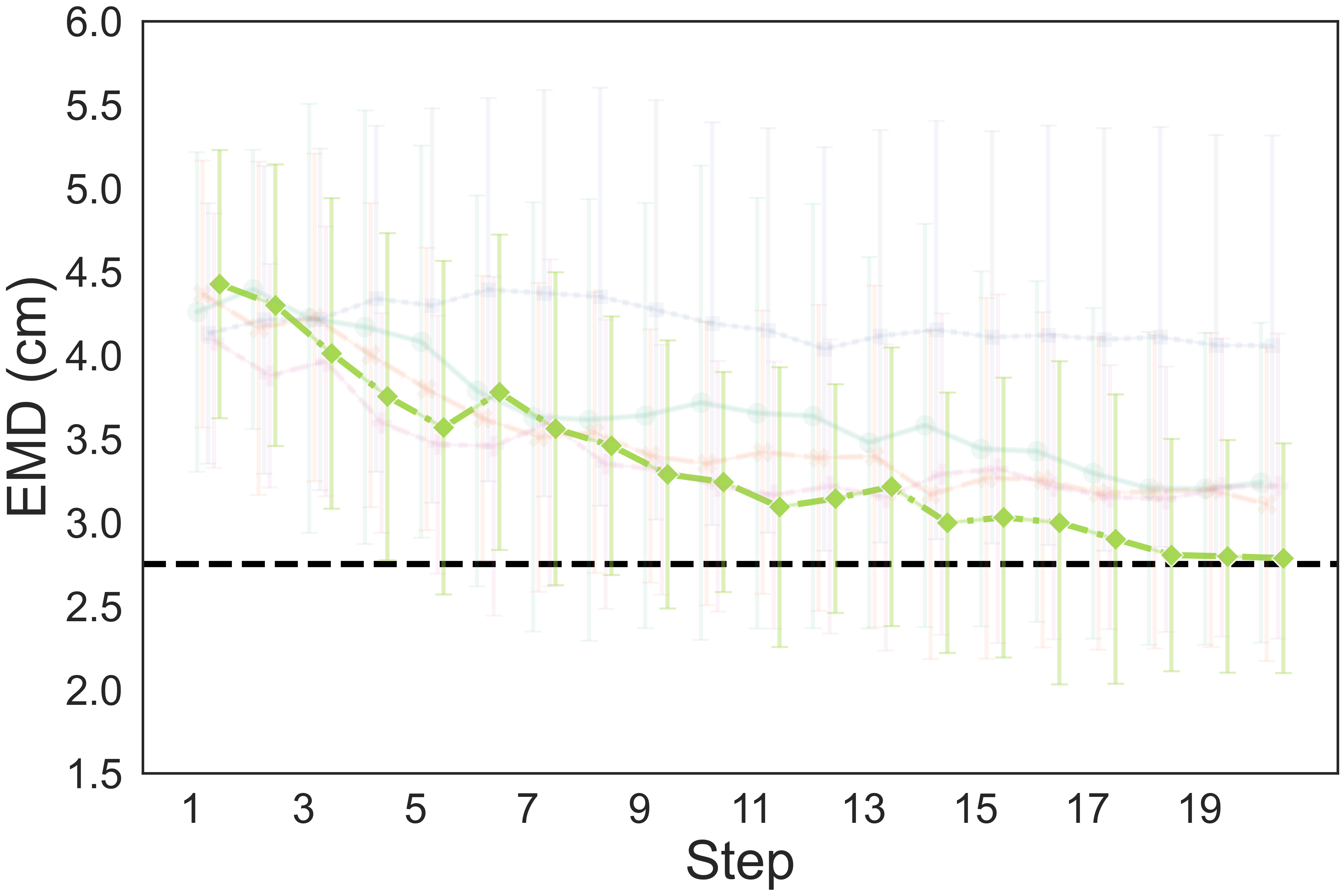
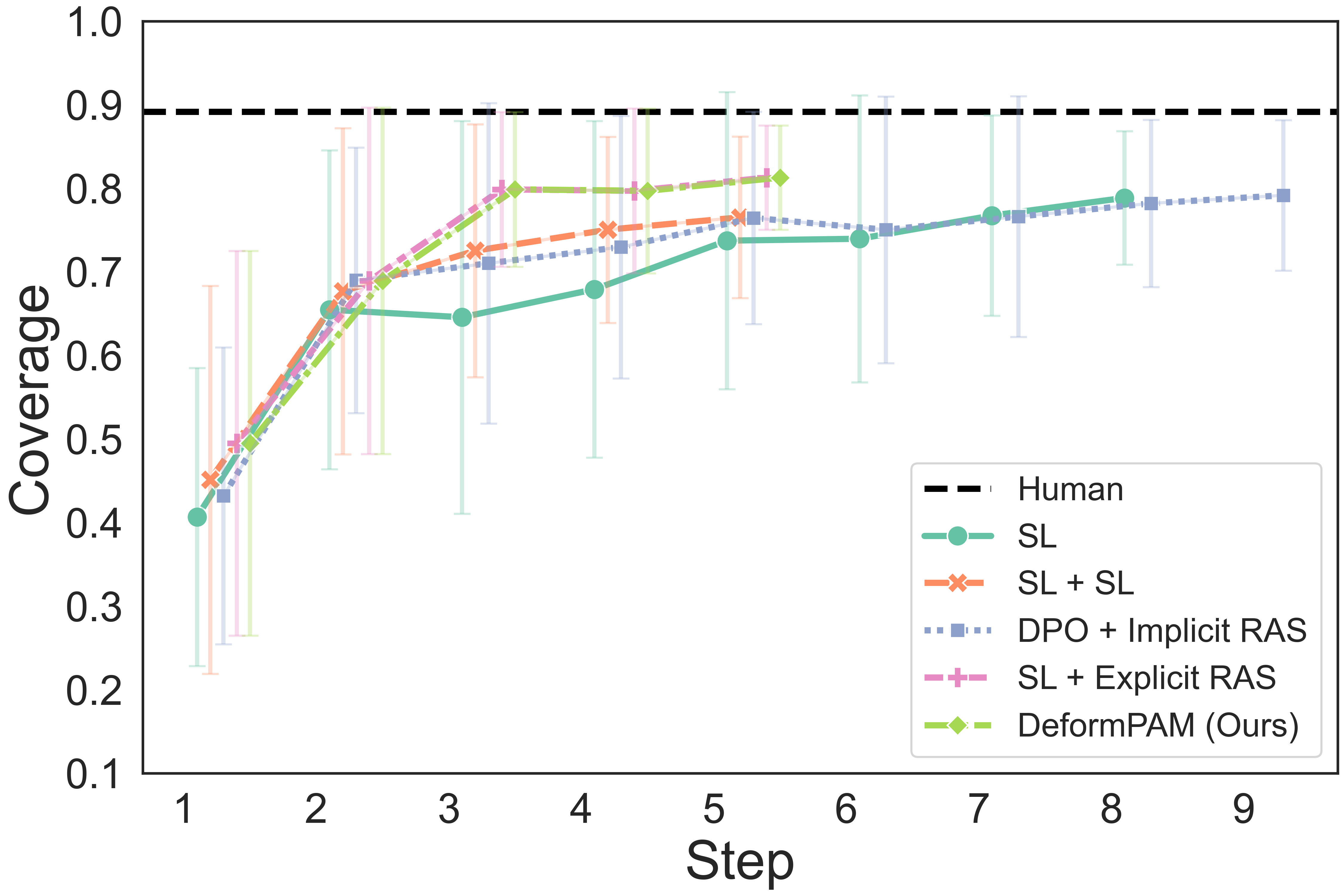
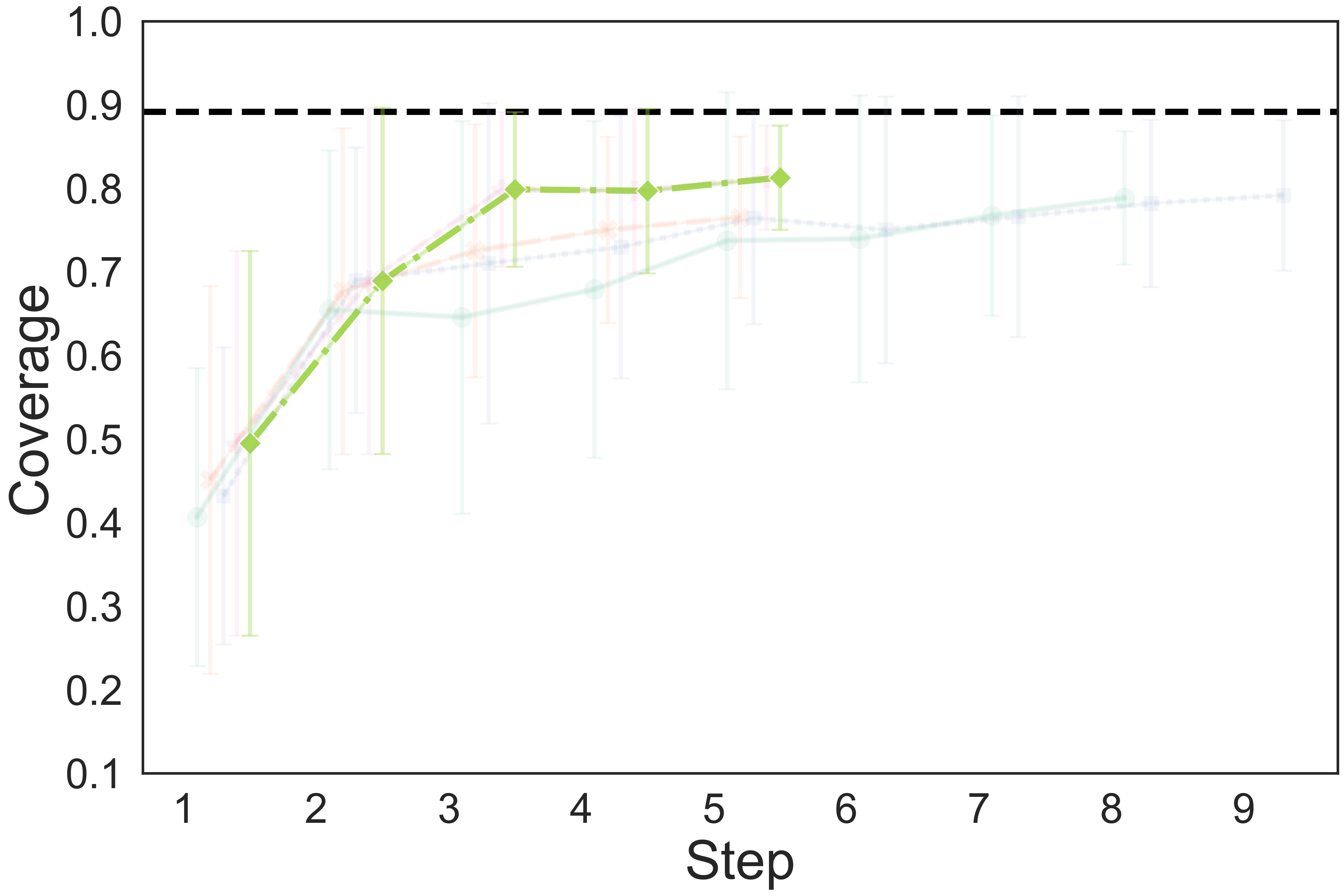
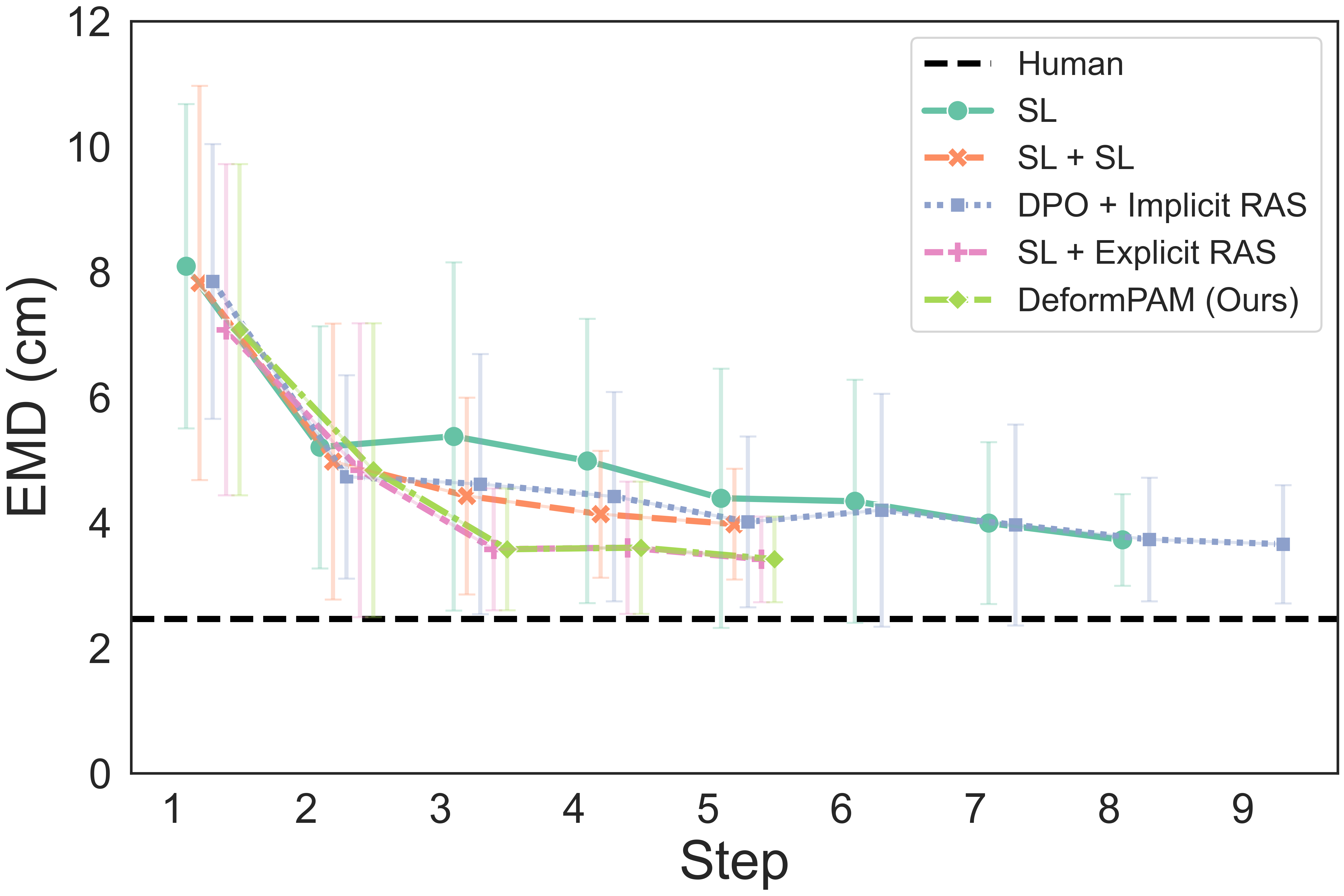
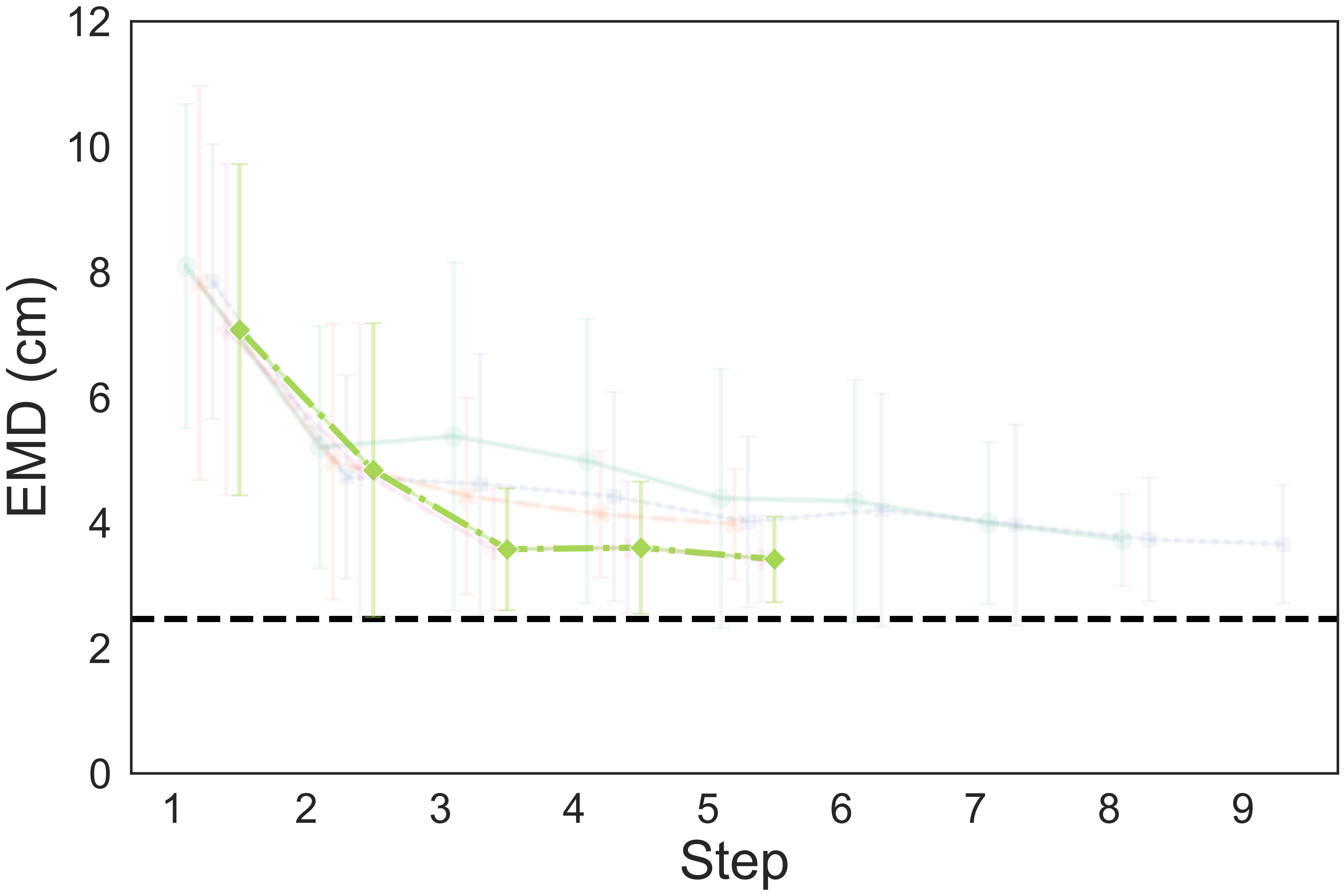
The quantitative results show that our method achieves a higher completion quality with fewer steps and exhibits reduced variance.
You can hover over the figure to highlight the curve of our method.
(a) Granular Pile Shaping
(b) Rope Shaping
(c) T-shirt Unfolding
Fig. 4: Quality metrics per step on the three tasks. The results are calculated on 20 trials. Each evaluation trial ends until the policy already reaches its optimal state or exceeds the maximum steps. SL, DPO, RAS stand for the supervised model, DPO-finetuned model, and reward-guided action selection.
The qualitative results also demonstrate the superiority of our method in terms of completion quality and variance.
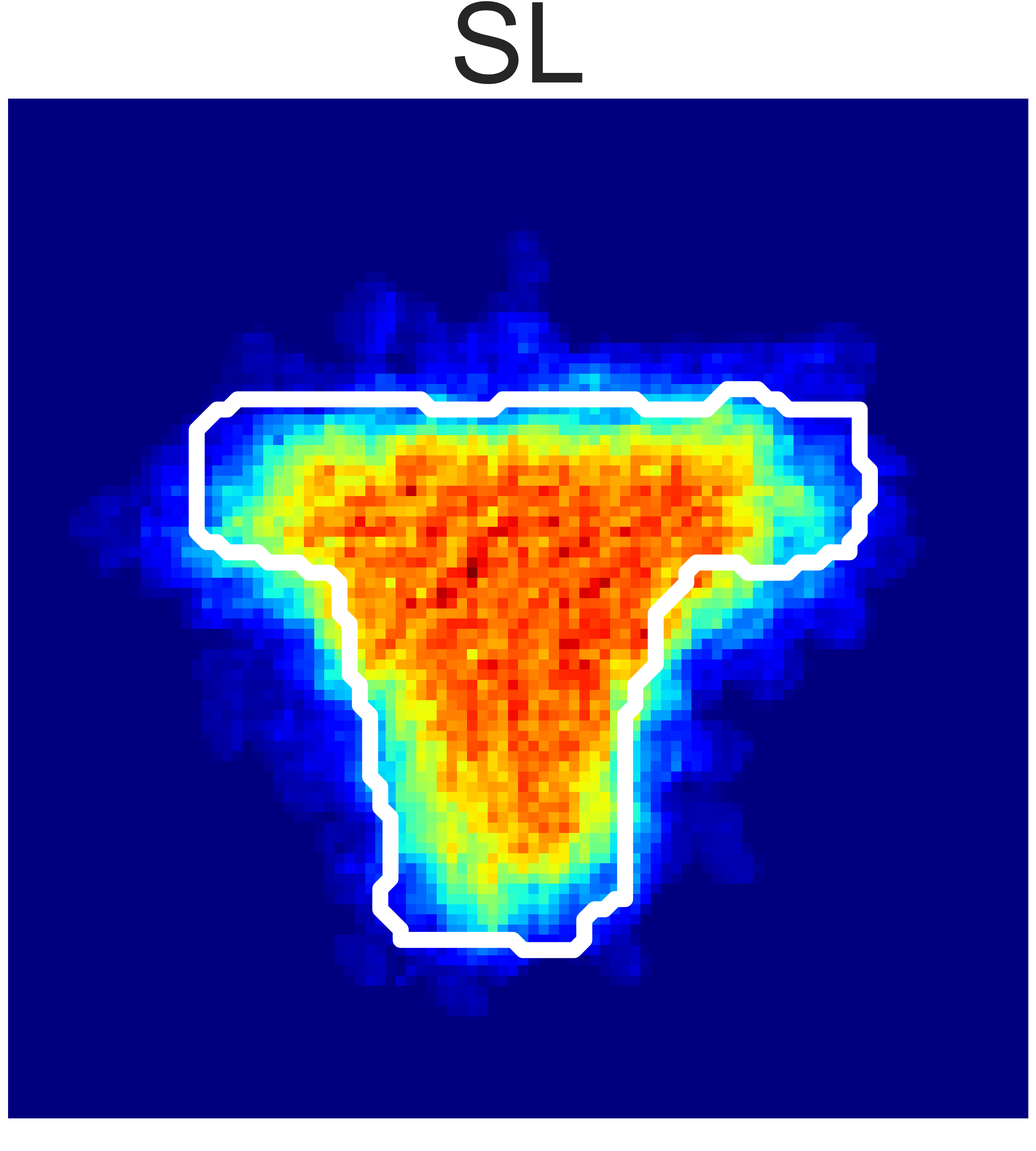
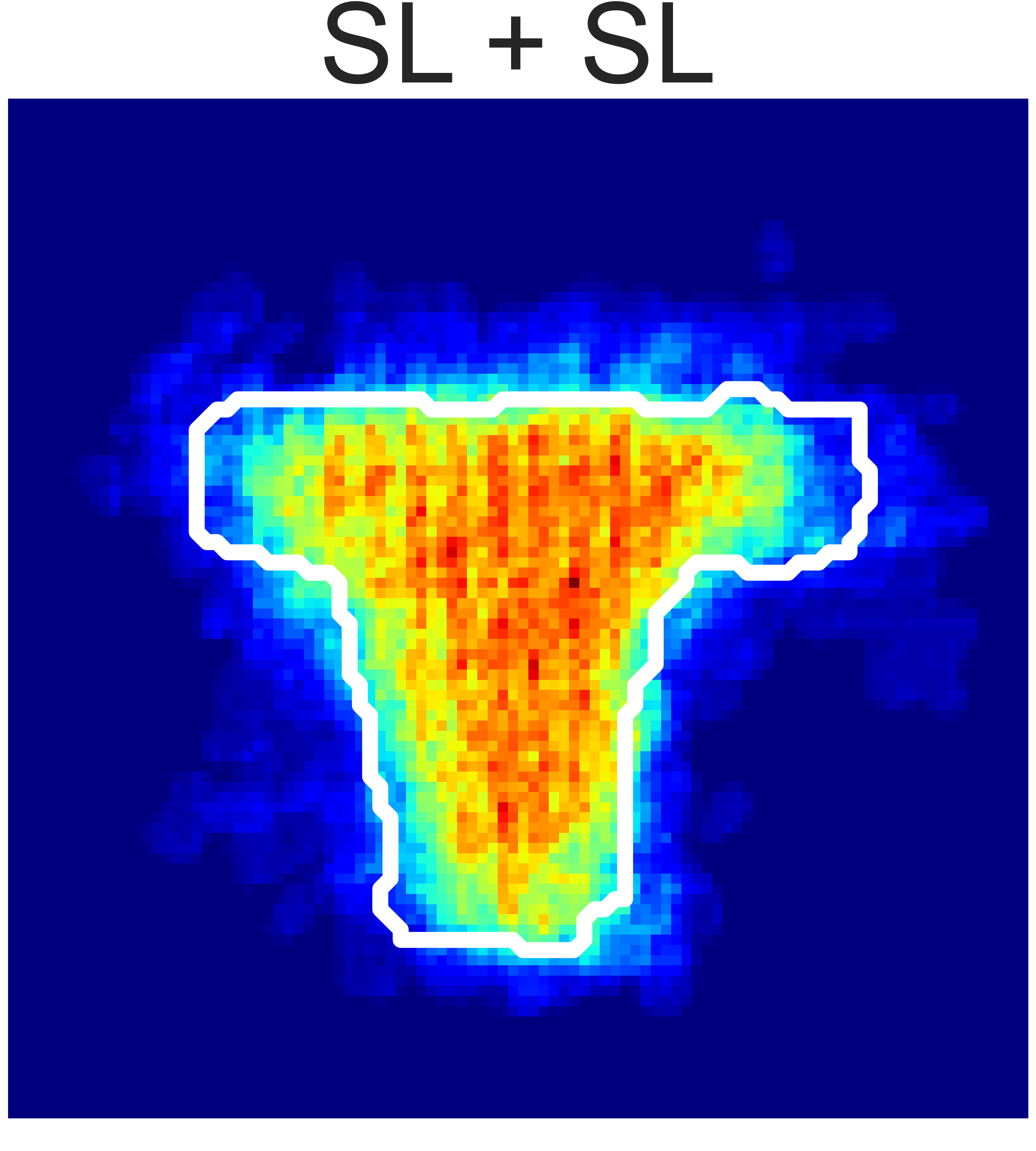
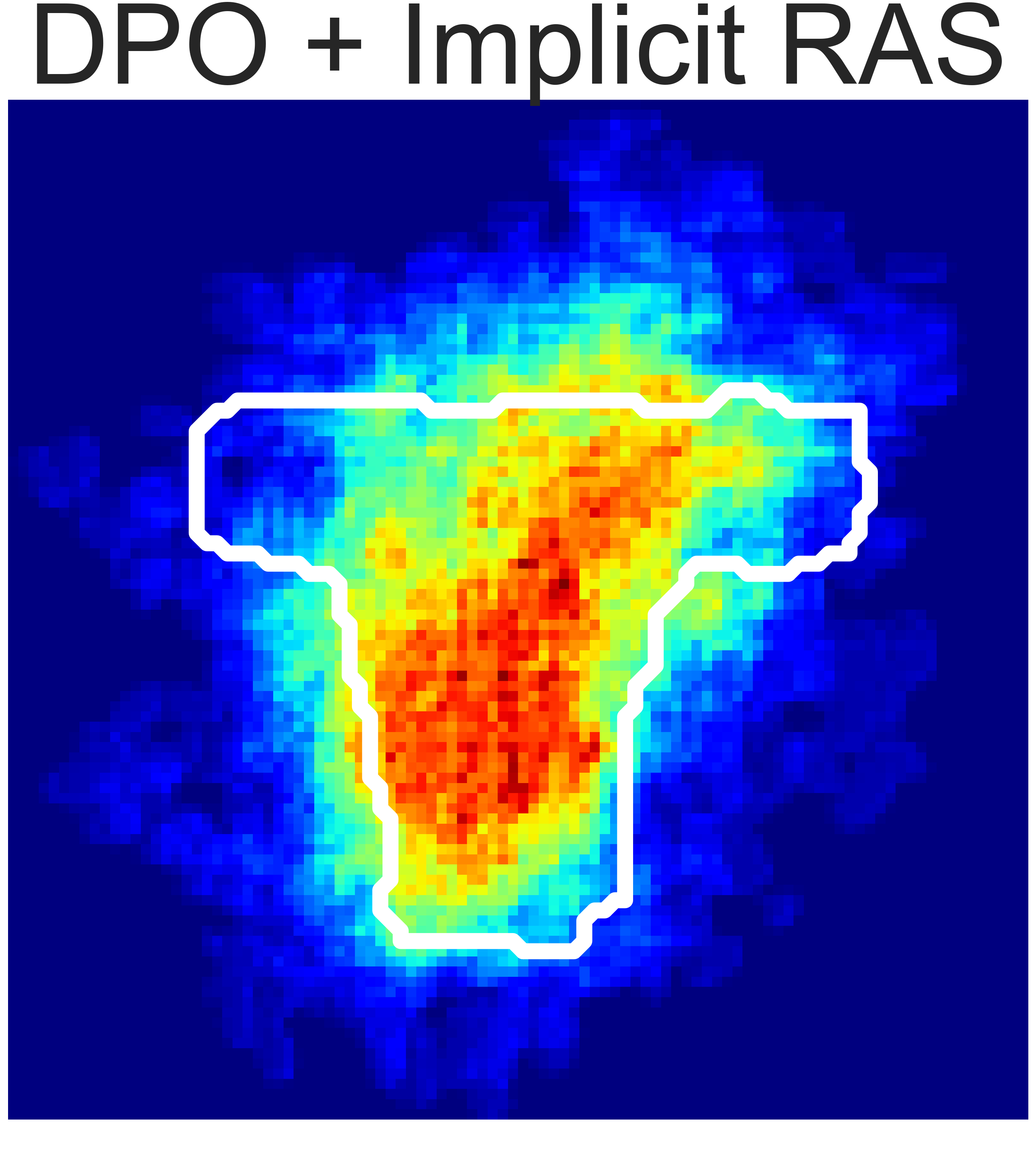
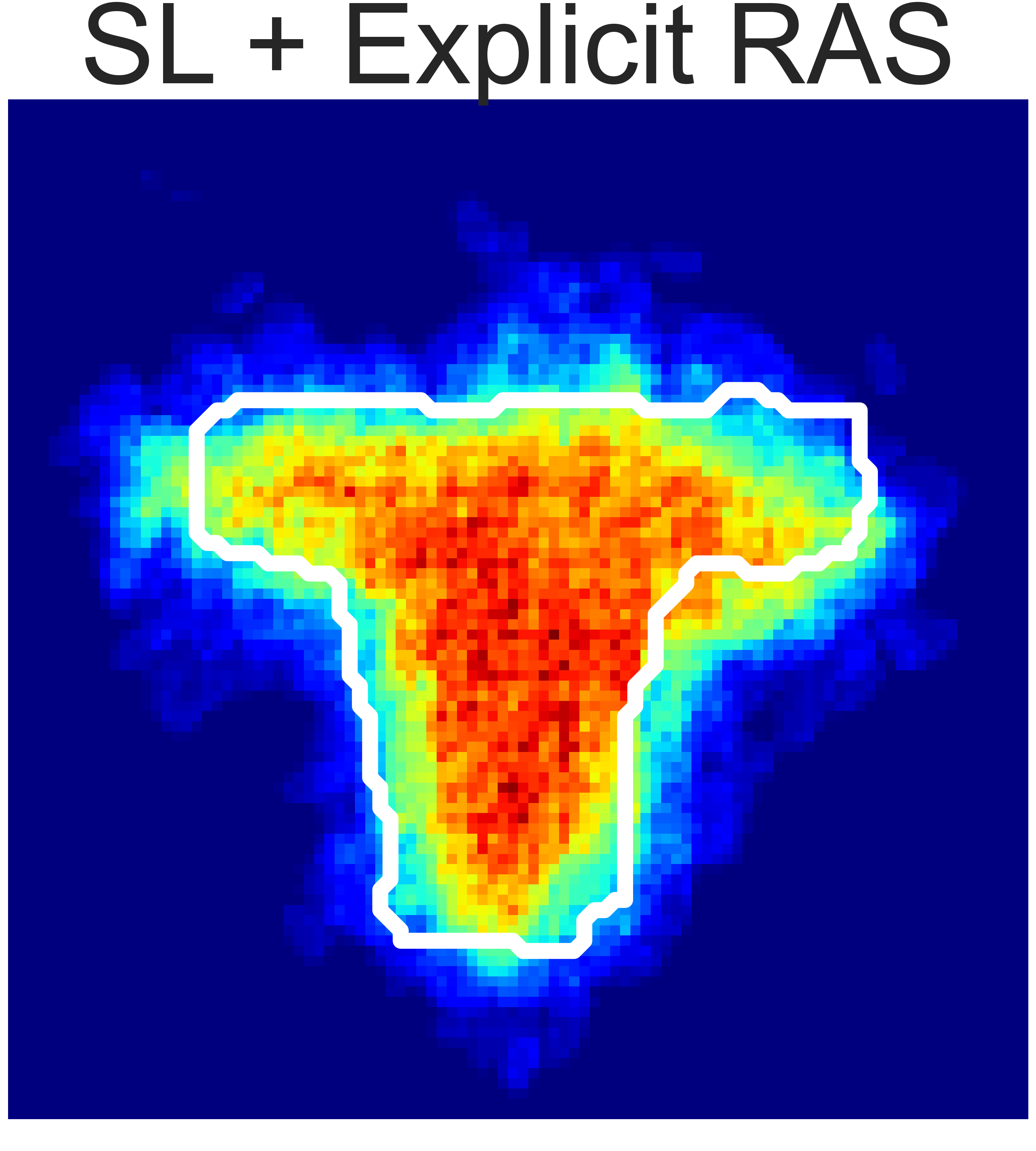
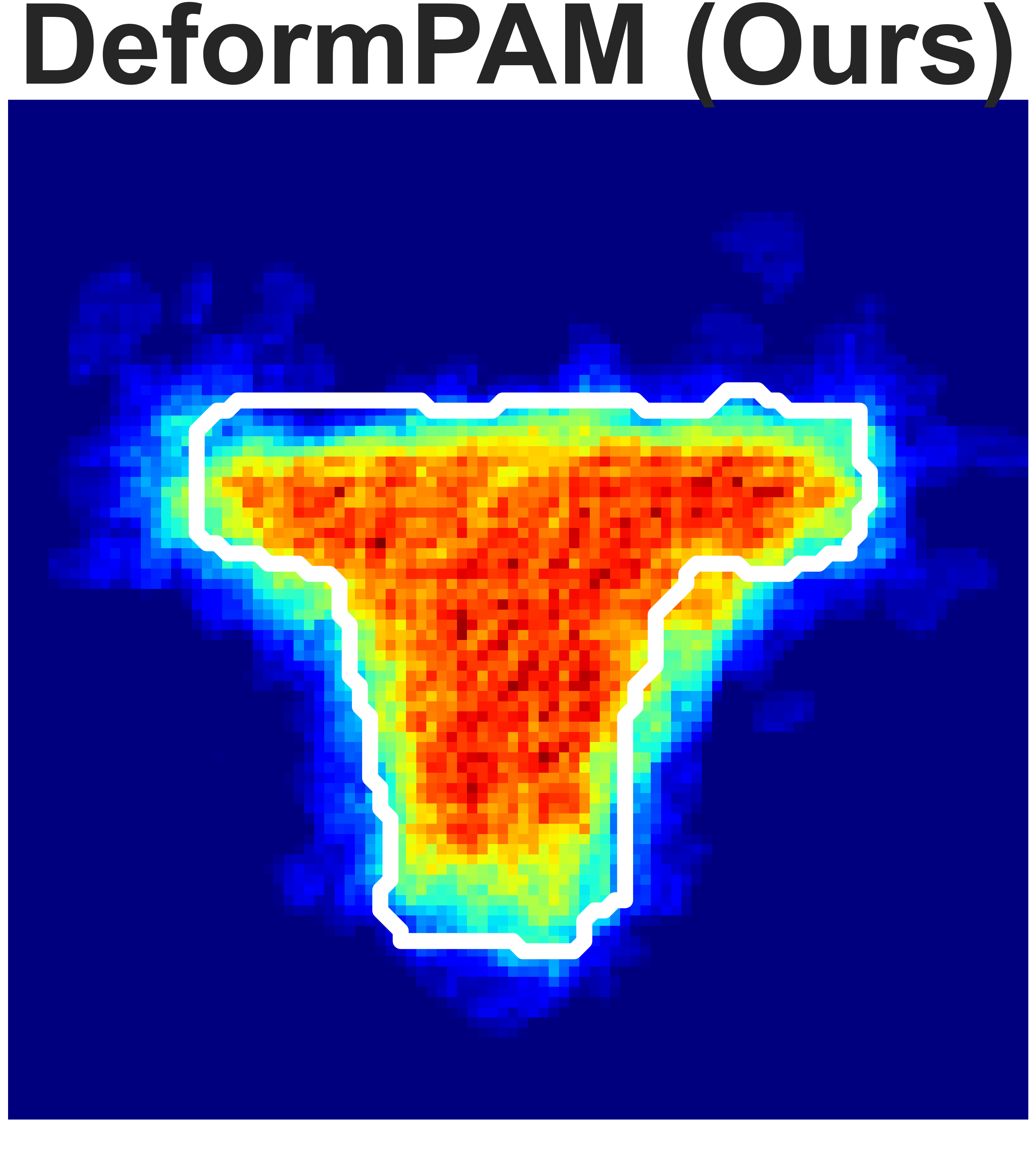
(a) Granular Pile Shaping
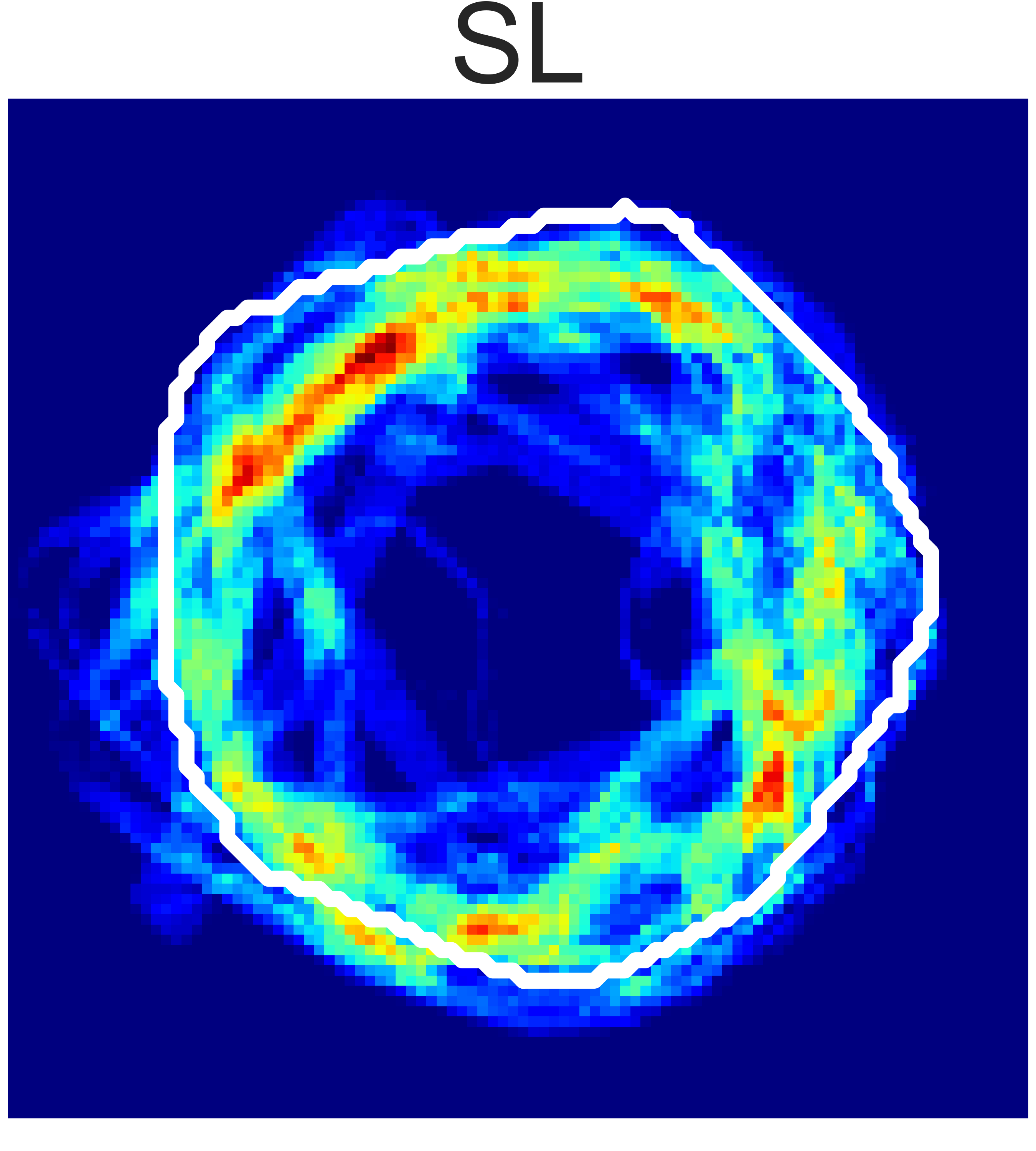
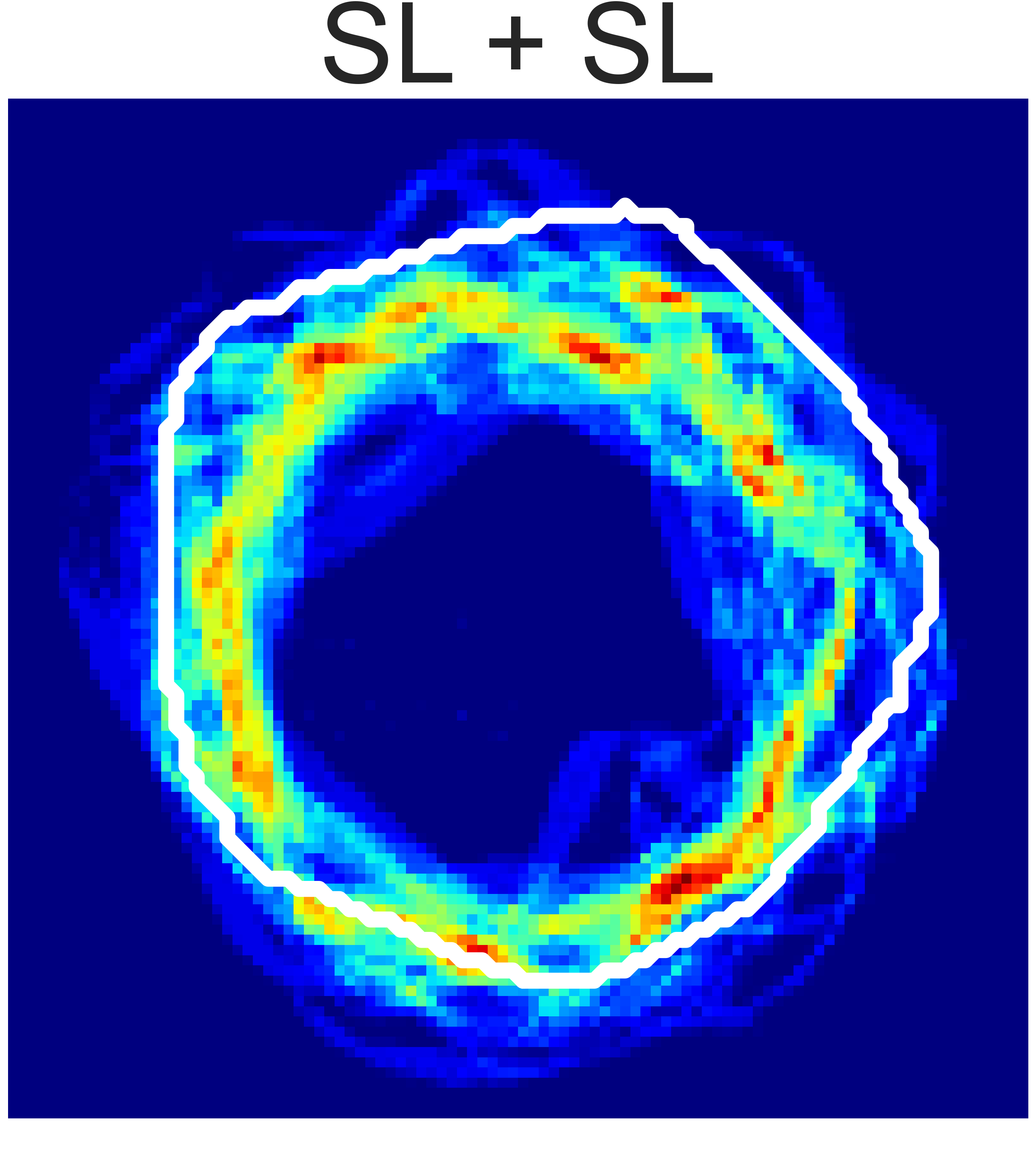
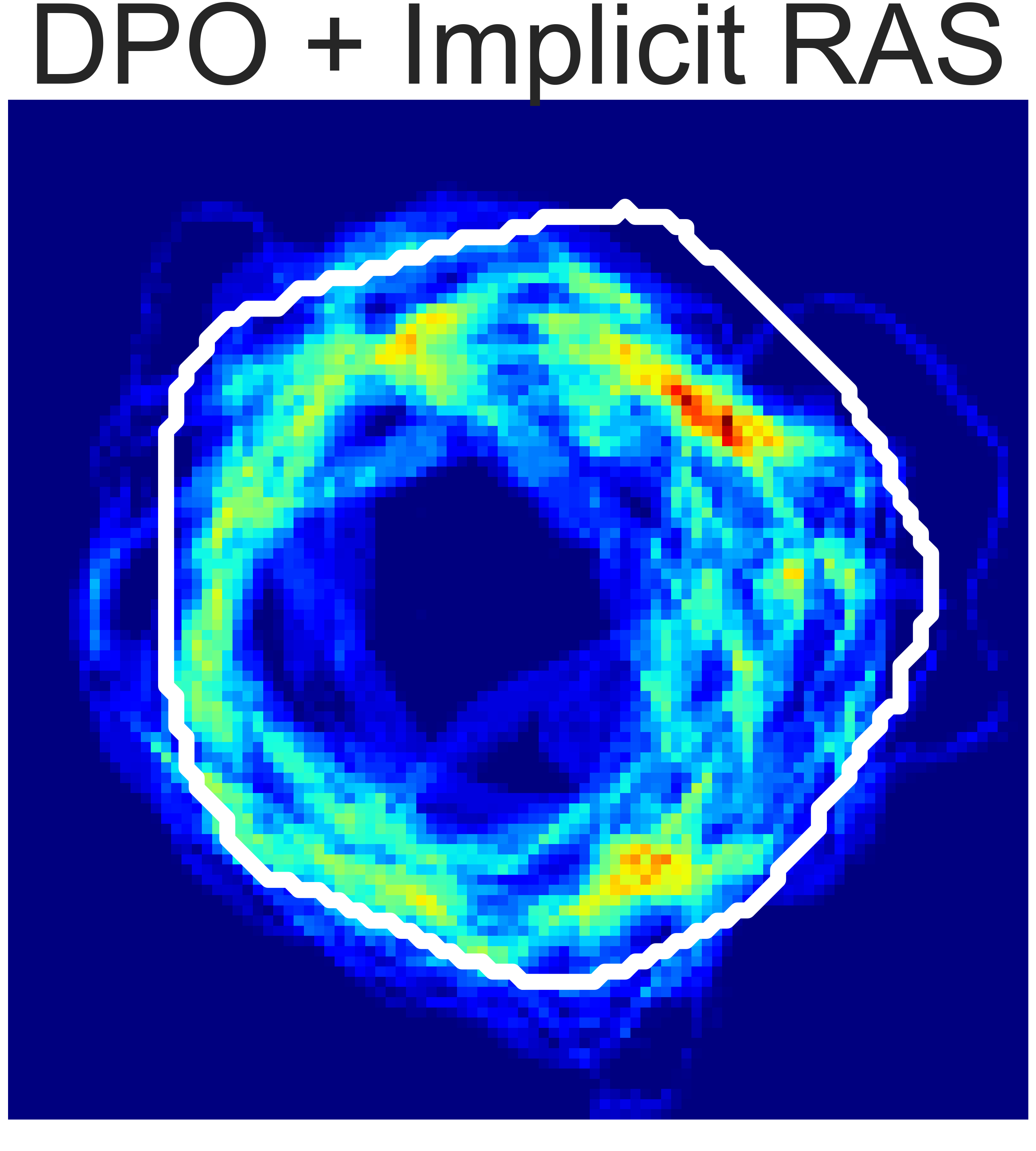
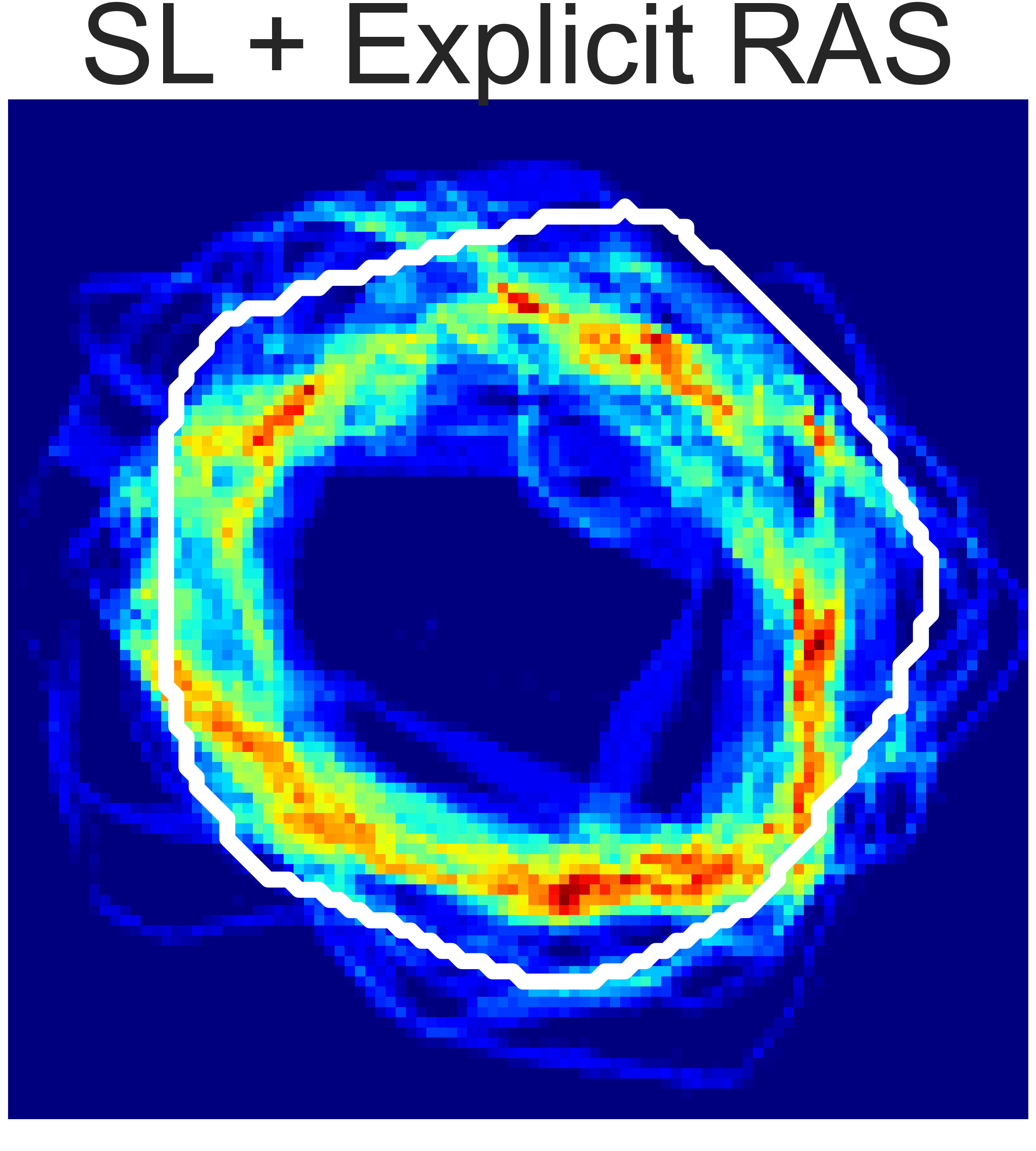

(b) Rope Shaping
Fig. 5: Final state heatmaps of 20 trials compared with the target state.
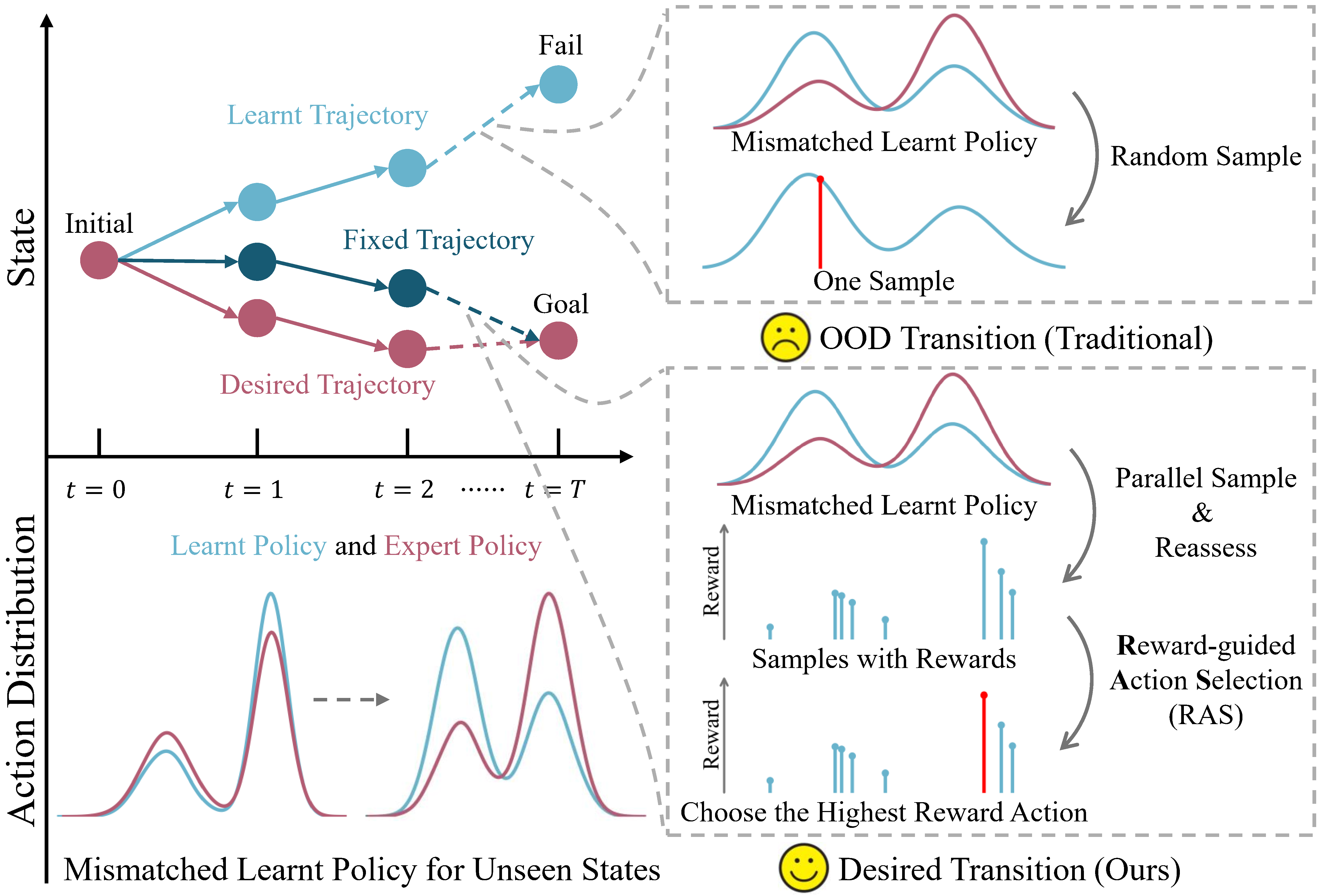
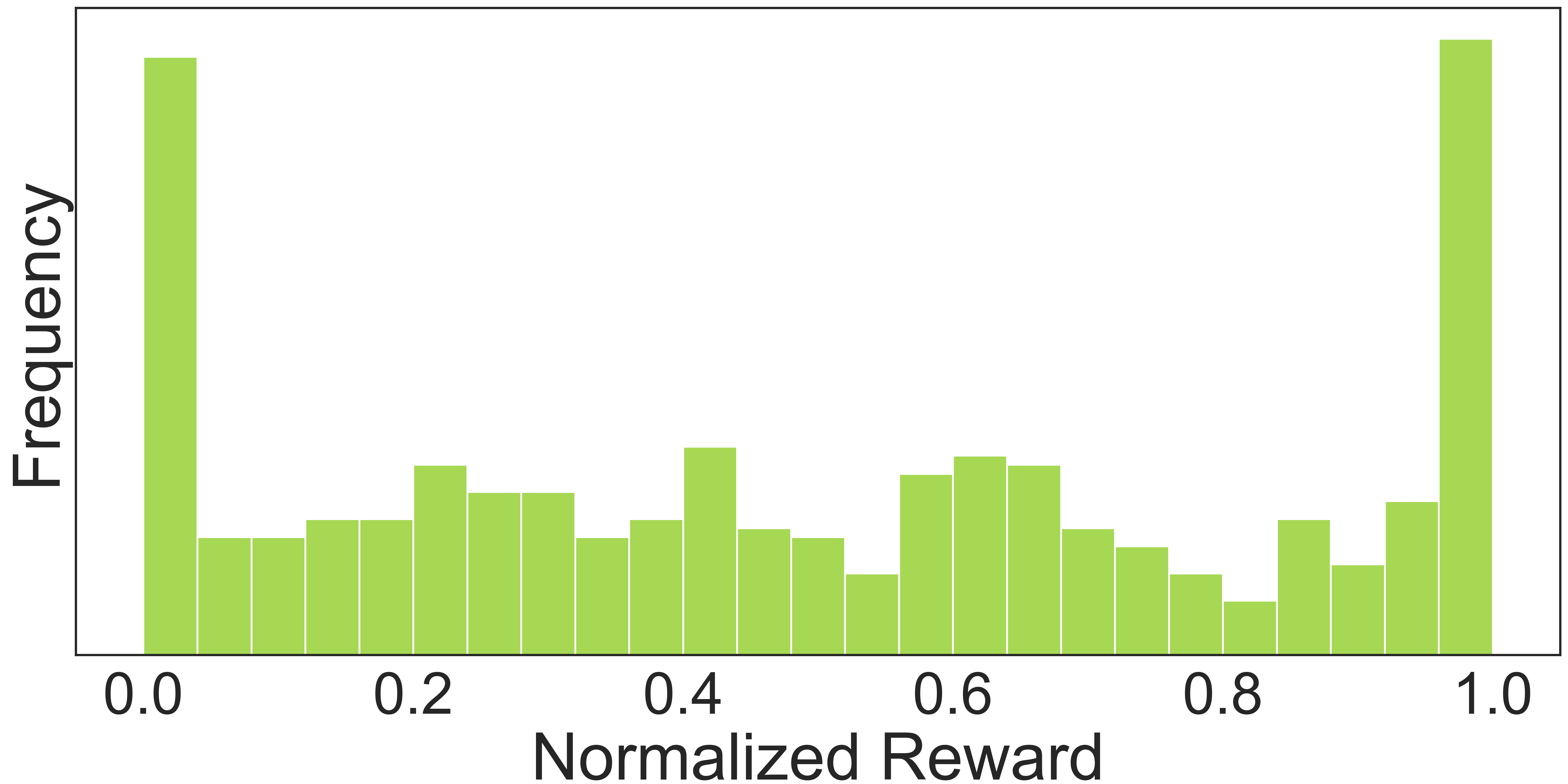
We analyzed the distribution of normalized implicit reward values during inference, as shown in Fig. 6a. This indicates that there is no positive correlation between the sampling probability of the action generation model and the predicted reward values, which suggests that employing reward-guided action selection can serve as a quality reassessment.
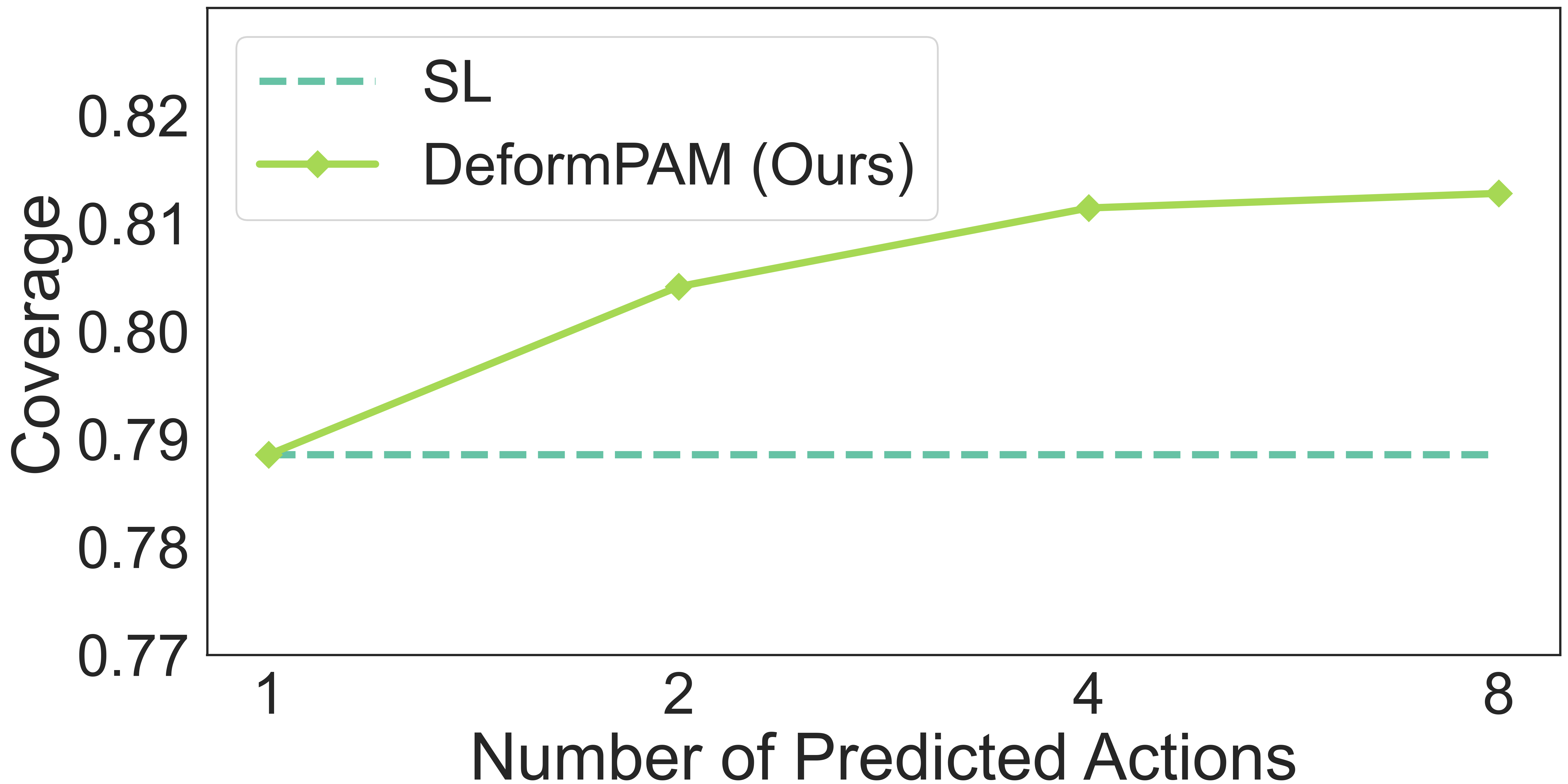
From another perspective, we compare the performance between random sampling and reward-guided action selection by adjusting the number N of predicted actions during inference in the T-shirt unfolding task and computing the final coverage. As shown in Fig. 6b, as \(N\) increases, the model’s performance gradually improves. This demonstrates that reward-guided action selection enables the model to select superior samples, thereby benefiting from a greater number of samples.
(a)
(b)
Fig. 6: (a) Normalized reward distribution during inference when sampling \(N = 8\) actions. (b) Average coverage for various numbers \(N\) of predicted actions during inference.
Compared with other primitive-based methods, our method achieves the target state with fewer steps without abnormal actions or getting stuck.
Green and Red indicate success and failure. The videos will be synchronized when clicking the play button.
Trial 1
Trial 2
Trial 3
Granular Pile Shaping (12×)
Trial 1
Trial 2
Trial 3
Rope Shaping (24×)
Trial 1
Trial 2
Trial 3
T-shirt Unfolding (8×)
We collect data and train the Diffusion Policy on two shaping tasks. The results indicate that the Diffusion Policy can easily get stuck when only a small amount of data is available. This may be due to the distribution shift causing the model to encounter unseen states, where the multi-modal action distribution of deformable objects makes the model confused. For example, in the rope shaping task, when both sides of the rope have curves, the model faces two opposing choices, creating challenges for learning.
Note that we also simplify the shaping tasks, such as by adding a reference line for the target state in the granular pile shaping task and using a stick for rope shaping, to reduce failures caused by contact-rich actions. The hardware settings are also different. For example, a wrist-mounted 2D camera and a third-person perspective 2D camera are used instead of the 3D camera.
Due to the difficulty of recording high-dynamic actions and precise position-based contact, we did not test the T-shirt Unfolding tasks.
stuck
success
stuck
success
stuck
success
Granular Pile Shaping (8×)
stuck
stuck
stuck
stuck
stuck
stuck
Rope Shaping (8×)
@article{chen2024deformpam,
title = {DeformPAM: Data-Efficient Learning for Long-horizon Deformable Object Manipulation via Preference-based Action Alignment},
author = {Chen, Wendi and Xue, Han and Zhou, Fangyuan and Fang, Yuan and Lu, Cewu},
journal = {arXiv preprint arXiv:2410.11584},
year = {2024}
}